Today I was asked to help with a curly document supply request. A distance student was looking for a particular article, which my colleagues had been unable to locate. Usually we think of document supply as resource sharing, but today was really more about resource finding. It’s also similar to reference queries about how to find journal articles, which we get all the time.
It wound up being so difficult—and interesting!—that I thought others might like to know how it was done. This is also partly so that if my colleagues decide they want me to present a training session on this, I’ve already got the notes written up… teehee.
The request
The details I received looked like this:
Journal Title Risk & Regulation
Publisher CARR LSE
Volume / Issue Issue 3
Part Date Spring 2002
Call Number
Title Japan: Land of the Rising Audit?
Article Author Michael Power
Pages 10 ff
My colleagues initially thought this was a book chapter request, but the book they’d found didn’t quite match these details, at which point they roped me into the search.
Catalogue search
Step 1: Search our local catalogue. This is standard for all document supply requests—you’d be surprised how often people ask for things we already have. I consider it a learning and teaching opportunity (and sometimes also a reminder that print books and serials still exist). In this instance, we didn’t have anything with this title in our catalogue.
Step 2: Search Libraries Australia, the national union catalogue. If another Australian library held this serial, we would request it on the patron’s behalf through the Libraries Australia Document Delivery (LADD) system, of which most Australian libraries are a member. I didn’t have an ISSN, so I had to go on title alone.
Good news: there is a record in LA for this serial, so I could confirm it exists. Bad news: no library in Australia holds it. (Records without holdings are common in LA, as many libraries use it as an acquisitions tool.)

Step 3: Search SUNCAT, the British serials union catalogue. I realised later that I didn’t really need to do this step, because the only extra info that LA didn’t have was a list of UK institutions that held copies. (Which I obviously couldn’t get at.) However, it wasn’t until this point that I noticed the note stating ‘Also available via the internet.’ Which got me thinking—is this an OA online journal? It would explain the lack of local holdings if it was just on the internet…
Web archive search
Step 4: Google the journal title. Yes, Google, like a real librarian.
Turns out the journal Risk & regulation is indeed published free and online by the London School of Economics, AND they have back issues online! … going back to 2003. The one I need is from 2002, because of course it is.
Step 5: Search the UK Web Archive. Knowing the journal was a) a UK title and b) online at some point, I then turned to web archives to find a copy. I searched on the article title, it being more distinctive than the journal title, and also because a more specific search would get me results faster. This brought me to an archived LSE news page from 2002.
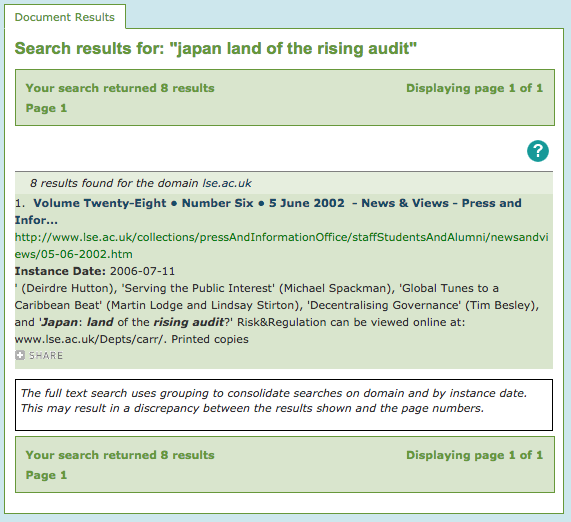
The LSE news page provided a link to the journal page—but the UK Web Archive hadn’t preserved it! Argh!
Step 6: Search the Wayback Machine. All was not lost, however. Because I was now armed with a dead URL that had once linked to the journal page I needed, I could go straight to the Wayback Machine, part of the Internet Archive, and simply plug in the URL to find archived copies of that page. The Wayback Machine recently launched a keyword search functionality, but it’s still a work in progress. My experience suggests this site functions best when you know exactly where to look.
I had to fiddle around with the URL slightly, but I eventually got to the journal landing page. Remembering that I needed issue 3 from Spring 2002, I clicked on the link to the relevant PDF—also archived!—and quickly located the article.

Step 7: Email article to student and give them the the good news. They thanked me and asked how I found it, so I gave them a shorter version of the above in the hope they might find it useful in future. I made sure to reassure them that this kind of thing is quite difficult and there’s often not necessarily a single place to search (they had wondered what search terms they ought to have used) and if they were stuck in future, just ask a librarian—it’s what we’re for. 🙂
Conclusions
Web archives aren’t usually the search target of choice for reference and document supply staff, but they are an absolute goldmine of public information, particularly for older online serials that may have vanished from the live web. Many researchers (and librarians, for that matter) don’t know much about web archives, if anything, so cases like this are a great way to introduce people to these incredible resources.
This was also a bit of a proud moment for me, I won’t lie. It’s so good to have moments like this every now and again—it helps me demonstrate there’s still a place for professional document hunters.