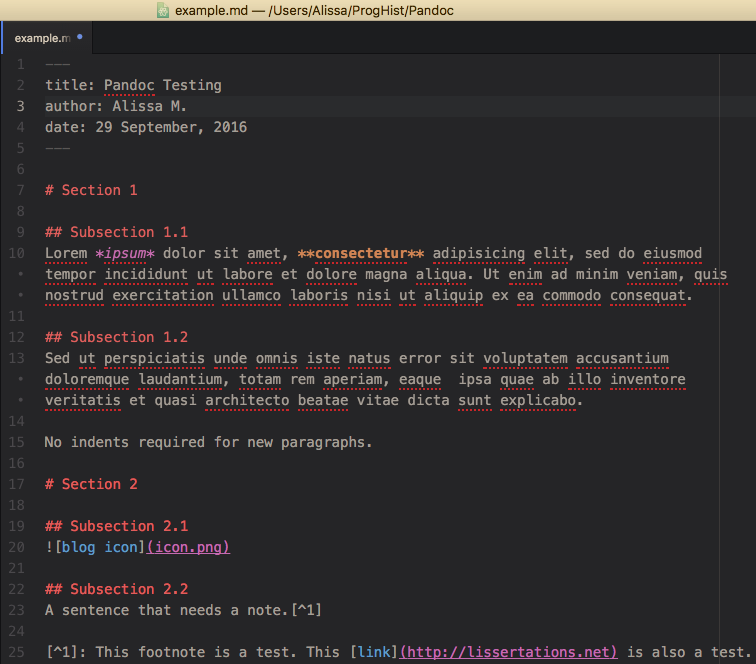
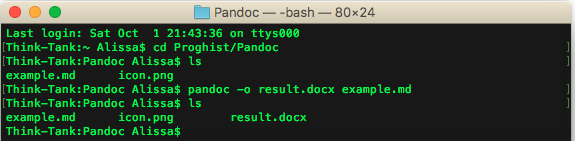
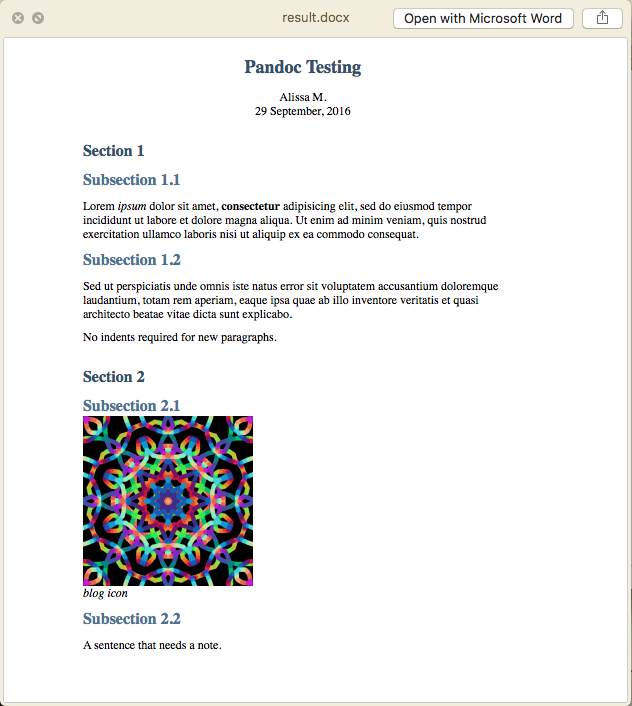
Another day, another depressing article about the future of libraries in the UK. I felt myself becoming predictably frustrated by the usual ‘libraries are glorified waiting rooms for the unemployed’ and ‘everything’s on the internet anyway’ comments.
I also found myself trying to come up with ways to do something about it. Don’t get me wrong, I like a good whinge as much as the next man, but whinging only sustains me for so long. Where possible I like to find practical solutions to life’s problems. The issue of mass library closures in the UK might seem too much for one librarian to solve—especially a student librarian on the other side of the world with absolutely no influence in UK politics. But I won’t let that put me off.
Consider the following: Google is our first port of call in any modern information search, right? When we want to know something, we google it. That’s fine. Who determines what appears in search results? Google’s super-secret Algorithm, harnessing an army of spiders to index most corners of the Web. How do web admins try and get their sites to appear higher in search results? Either the dark art of search engine optimisation (SEO), which is essentially a game of cat-and-mouse with the Algorithm, or the fine art of boutique metadata, which is embedded in a Web page’s <meta> tags and used to lure spiders.
Despite falling patronage and the ubiquity of online information retrieval, libraries are absolutely rubbish at SEO. When people google book or magazine titles (to give but one example), libraries’ OPACs aren’t appearing in search results. People looking for recreational reading material are libraries’ target audience, and yet we’re essentially invisible to them.
Even if I accept the premise that ‘everything’s on the internet’ (hint: no), how do people think content ends up on the internet in the first place? People put things online. Librarians could put things online if their systems supported them. Librarians could quite easily feed the internet and reclaim their long-lost status as information providers in a literal sense.
The ancient ILS used by my workplace is an aggravating example of this lack of support. If our ILS were a person it would be a thirteen-year-old high schooler, skulking around the YA section and hoping nobody notices it’s not doing much work. Our OPAC, for reasons I really don’t understand, has a robots.txt warding off Google and other web crawlers. The Web doesn’t notice it and patrons don’t either. It doesn’t help that MARC is an inherently web-unfriendly metadata standard; Google doesn’t know or care what a 650 field is, and it’s not about to start learning.
(Screenshot below obscures the name of my workplace in the interests of self-preservation)
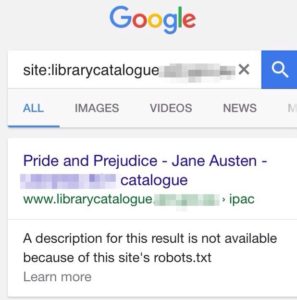
Down with this sort of thing.
Perhaps in recognition of this problem, vendor products such as SirsiDynix’s Bluecloud Visibility promise to convert MARC records to linked data in Bibframe and make a library’s OPAC more appealing to web crawlers. I have no idea if this actually works or not (though I’m dying to find out). For time-poor librarians and cash-strapped consortia, an off-the-shelf solution would have numerous benefits.
But even the included Google screenshot in the article, featuring a suitably enhanced OPAC, has its problems. Firstly, the big eye-catching infobox to the right makes no mention of the library, but includes links to Scribd and Kobo, who have paid for such prominence. Secondly, while the OPAC appears at the top of the search results, the blurb in grey text includes boring bibliographical information instead of an eye-catching abstract, or even something like ‘Borrow “Great Expectations” at your local library today!’. Surely I’m not the only one who notices things like this…?
I’m keen to do a lot more research in this area to determine whether the promise of linked data will make library collections discoverable for today’s users and bring people back to libraries. I know I can’t fix the ILS. I can’t re-catalogue every item we have. I can’t even make a script do this for me. For now, research is the most practical thing I can do to help solve this problem. Perhaps one day I’ll be able to do more.
Further reading
Fujikawa, G. (2015). The ILS and Linked Data: a White Paper. Emeryville, CA: Innovative Interfaces. Retrieved from https://www.iii.com/sites/default/files/Linked-Data-White-Paper-August-2015.pdf
Papadakis, I. et al. (2015). Linked Data URIs and Libraries: The Story So Far. D-Lib 21(5-6), May-June 2015. Retrieved from http://dlib.org/dlib/may15/papadakis/05papadakis.html
Schilling, V. (2012). Transforming Library Metadata into Linked Library Data: Introduction and Review of Linked Data for the Library Community, 2003–2011. ALCTS Research Topics in Cataloguing and Classification. Retrieved from http://www.ala.org/alcts/resources/org/cat/research/linked-data